CH3 常見的probability distributions
要利用第二章操作probabilities的規則,為了使用這些規則,我們需要定義一些機率分布。選擇機率分布的依據是取決於我們正在建模的數據x的領域。
當我們在使用模型去擬合資料的時候,我們需要知道我們對擬合的不確定性有多大,而這個不確定性被表示為”對擬合模型的參數的機率分布”。也就是說每當一個模型在擬合資料的時候,都存在一個與之相關聯的參數的第二個機率分布。
例如 Dirichlet 是用於categorical distribution的參數的模型。在這種狀況下 Dirichlet的參數會被稱為超參數(hyperparameters)。更一般地說,超參數確定了原始分布參數的機率分布的形狀。
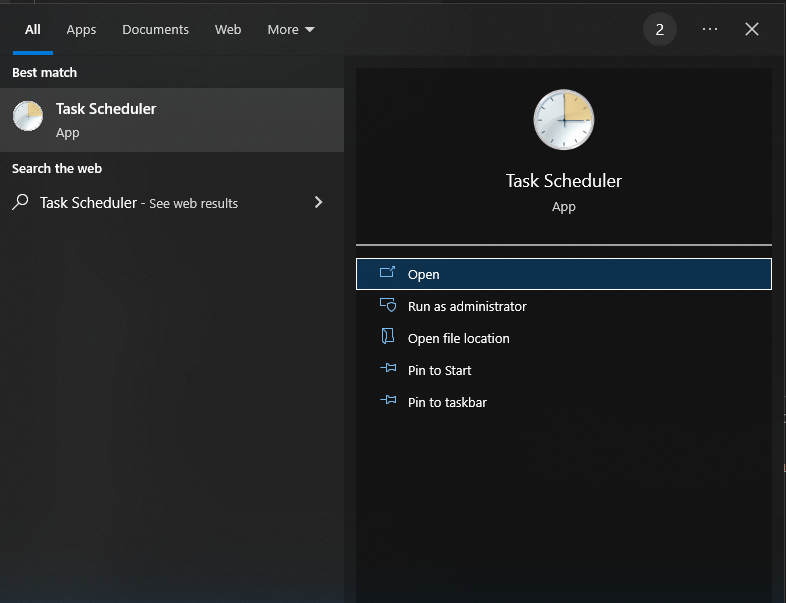
| Distribution |
Domain |
Parameters modeled by |
| Bernoulli |
x ∈ {0, 1} |
beta |
| categorical |
x ∈ {1, 2, . . . , K} |
Dirichlet |
| univariate normal |
x ∈ R |
normal inverse gamma |
| multivariate normal |
x ∈ Rk |
normal inverse Wishart |
|Distribution | Domain | Parameters modeled by |
Bernoulli | x ∈ {0, 1} | beta
categorical | x ∈ {1, 2, . . . , K} | Dirichlet
univariate normal | x ∈ R | normal inverse gamma
multivariate normal | x ∈ Rk | normal inverse Wishart
CH3.1 Bernoulli distribution
Bernoulli distribution是一個離散分布用於模擬二元試驗。他用於描述只有兩中輸出結果的狀況,$x \in {0, 1}$分別代表是(success)、否(failure)。在機器視覺中,Bernoulli distribution可以用來模擬資料。例如,它可以描述一個像素具有大於或小於128的強度值的概率。或者是用來描述世界的狀態。例如,它可以描述圖像中臉部存在或不存在的概率。
Bernoulli distribution只有一個parameter $\lambda \in [0, 1]$,用來描述觀察到success的機率。Bernoulli distribution的機率質量函數如下
$$Pr(x = 0) = 1 - \lambda$$
$$Pr(x = 1) = \lambda$$
我們可以用另一種表達方式,將0或1帶入就可以得到上面其中一條式子。
$$Pr(x) = \lambda^x(1-\lambda)^{1-x}$$
或是另一種等價的表達方式
$$Pr(x) = Bern_x[\lambda] $$
CH3.2 Beta distribution
Beta distribution是一個連續分布,他是定義在單變量$\lambda$上的連續分布,$\lambda \in [0, 1]$。它適用於表示伯努利分布參數$\lambda$的不確定性。
beta distribution 有兩個parameter$\alpha, \beta \in [0, \infty]$,兩個parameter均為正數並且影響distribution的形狀。以數學表達如下
$$Pr(\lambda) = \frac{\Gamma[\alpha + \beta]}{\Gamma[\alpha]\Gamma[\beta]}\lambda^{\alpha-1}(1-\lambda)^{\beta-1}$$
式子中的$\Gamma[]$代表gamma function,定義為
$$\Gamma[z] = \int_0^{\infty}t^{z-1}e^{-t}dt$$
,他與階乘密切相關,因此對於正數的積分$\Gamma[z] = (z - 1)!$而且$\Gamma[z+1] = z\Gamma[z]$ 。
beta distribution還有更簡單的表達式
$$Pr(\lambda) = Beta_{\lambda}[\alpha, \beta]$$
CH3.3 Catagorical distribution
Catagorical distribution是一個離散分布,他用來決定K個可能結果之一的概率。因此Bernoulli distribution是Catagorical distribution的一種特例,也就是只有兩種可能結果的Catagorical distribution。在機器視覺中也經常出現多個離散值取一個的情況,例如依照照片可能是{car,motorbike,van,truck}的其中一個。
對於有K種結果的Catagorical distribution,Catagorical distribution會一個$K \times 1$的參數的向量$\lambda = [\lambda_1, \lambda_2 … , \lambda_K]$其中$\lambda_K \in [0, 1]$而且$\sum^K_{k=1}\lambda_k = 1$Catagorical distributiond可以寫成
$$Pr(x = k) = \lambda_k$$
更簡短的可以寫成
$$ Pr(x) = Cat_x[\lambda]$$
或者,我們可以將數據看作取值$x \in {e_1, e_2, …,e_K}$,其中$e_k$是第k個單位向量;除了第k個元素為1之外,$e_k$的所有元素都為零。寫成式子如下
$$Pr(x=e_k) = \prod^K_{j=1}\lambda_k^{x_j} = \lambda_k$$
其中$x_j$是$x$的第j個元素。
CH3.4 Dirichlet distribution
Dirichlet distribution 是一個定義在K個連續值$\lambda_1 … \lambda_K$上的分佈,其中$\lambda_k \in [0, 1]$而且$\sum^K_{k=1}\lambda_k = 1$。因此他很適合用來作為定義Catagorical distribution的參數分布。
在$K$個維度上的Dirichlet distribution有$K$個parameter $\alpha_1 … \alpha_K$,每一個都可以是正數或是零。parameters之間的相對值決定了 expected values $E[\lambda_1] … E[\lambda_K]$。parameters的絕對值決定了Dirichlet distribution的集中度。他的機率密度函數如下
$$Pr(\lambda_{1…L}) = \frac{\Gamma[\sum^K_{k=1}\alpha_k]}{\prod^K_{k=1}\Gamma[\alpha_k]}\prod^K_{k=1}\lambda_k^{\alpha_k-1}$$
更簡短的寫法
$$Pr(\lambda_{1…K}) = Dir_{\lambda_{1…K}}[\alpha_{1…K}]$$
如同Bernoulli distribution是Catagorical distribution的特例,所以Beta distribution是Dirichlet distribution的特例,也就是$K=2$的Beta distribution。
3.5 Univariate normal distribution
Univariate normal distribution 或是 Gaussian distribution 是一個定義在實數上$x \in [-\infty, \infty]$的連續分佈。
在計算機視覺中,常常忽略像素強度被量化的事實,並使用連續的正態分佈模型來建模。
Normal distribution有兩個parameter,平均數$\mu$和變異數$\sigma^2$,平均數$\mu$決定了分佈的中心的位置,變異數$\sigma^2$決定了分佈的寬度。Normal distribution的機率密度函數如下
$$Pr(x|) = \frac{1}{\sqrt{2\pi\sigma^2}}exp{-\frac{1}{2\sigma^2}(x-\mu)^2}$$
或是更簡單的寫法
$$Pr(x) = Norm_x[\mu, \sigma^2]$$
3.6 Normal-scaled inverse gamma distribution
Normal-scaled inverse gamma distribution是一個定義在一對實數$\mu, \sigma$上的連續分佈,他的機率密度函數如下,其中$\mu$可以為正為負,但是$\sigma$必須為正。
Normal-scaled inverse gamma distribution有四個parameter,$\alpha, \beta, \gamma, \delta$,其中$\alpha, \beta, \gamma$必須為正,而$\delta$可以為正為負。機率密度函數如下:
$$Pr(\mu, \sigma^2) = \frac{\sqrt{\gamma}}{\sigma\sqrt{2\pi}}\frac{\beta^\alpha}{\Gamma[\alpha]}(\frac{1}{\sigma^2})^{\alpha + 1}exp[-\frac{2\beta + \gamma(\delta - \mu)^2}{2\sigma^2}]$$
或者是寫成
$$Pr(\mu, \sigma^2) = NormInvGam_{\mu, \sigma^2}[\alpha, \beta, \gamma, \delta]$$
3.7 Multivariate normal distribution
multivariate normal 也就是 D-dimensional Gaussian distribution,他的維度可以表示成D個元素 $x_1, … x_D$每個維度都是連續並且介於$[-\infty, \infty]$。而univariate normal distribution是multivariate normal distribution的特例,也就是$D=1$。
在機器視覺中,多變量正態分佈可以用來模擬圖像區域內 D 個像素的強度的聯合分佈。
世界的狀態也可以用這個分佈來描述。例如,多變量正態分佈可以描述場景中物體的三維位置(x、y、z)的聯合不確定性。
multivariate normal distribution有兩個parameter,平均數向量$\mu$ 以及covariance $\Sigma$。其中$\mu$是一個$D \times 1$的向量來描述分布的平均值。而covariance $\Sigma$是一個$D \times D$的正定矩陣,因此對於任何實數向量$z$而言,$z^T\Sigma z$都是正數。機率密度函式如下
$$Pr(x) = \frac{1}{\sqrt{(2\pi)^D|\Sigma|}}exp[-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu)]$$
或是更簡短一點
$$Pr(x) = Norm_x[\mu, \Sigma]$$
3.8 Normal inverse Wishart distribution
normal inverse Wishart distribution是一個定義在$D \times 1$的向量 $\mu和$D \times D$的矩陣 \Sigma$上的連續分佈。他適合用來描述 multivariate normal distribution 的參數的不確定性。normal inverse Wishart distribution有四個參數,$\alpha, \Psi, \gamma, \delta$,其中$\alpha$和$\gamma$為正純量,$\delta$為$D \times 1$的向量,$\Psi$為$D \times D$的正定矩陣。機率密度函數如下
$$\operatorname{Pr}(\boldsymbol{\mu}, \boldsymbol{\Sigma})=\frac{\gamma^{D / 2}|\boldsymbol{\Psi}|^{\alpha / 2} \exp \left[-0.5\left(\operatorname{Tr}\left[\boldsymbol{\Psi} \boldsymbol{\Sigma}^{-1}\right]+\gamma(\boldsymbol{\mu}-\boldsymbol{\delta})^T \boldsymbol{\Sigma}^{-1}(\boldsymbol{\mu}-\boldsymbol{\delta})\right)\right]}{2^{\alpha D / 2}(2 \pi)^{D / 2}|\boldsymbol{\Sigma}|^{(\alpha+D+2) / 2} \Gamma_D[\alpha / 2]}$$
其中$\Gamma_D[\bullet]$是multivariate gamma function and而$\operatorname{Tr}[\Psi]$回傳矩陣的迹(trace)。更簡單的寫法如下
$$Pr(\mu, \Sigma) = NormInvWish_{\mu, \Sigma}[\alpha, \Psi, \gamma, \delta]$$
很難將normal inverse Wishart distribution分佈可視化,但很容易抽樣並檢查樣本:每個樣本是一個常態分佈的平均值和協方差。
3.9 Conjugacy
在前面幾節有提到有些distribution可以呈現另一個distribution參數的機率分布。因為這些分布之間都有Conjugacy的關係。例如beta distribution conjugate Bernoulli distribution。Dirichlet conjugate categorical。當我們將兩個有Conjugacy的distribution相乘,結果將與共軛具有相同形式的新分佈成正比。例如
$$ Bern_x[\lambda]\times Beta_\lambda[\alpha, \beta] = \kappa(x, \alpha, \beta)\times Beta_\lambda[~{\alpha}, ~{\beta}]$$
在這裡$\kappa$是一個對於所關心的變量$\lambda$來說是常數的縮放因子。
conjugate重要的原因是因為在學習(擬合分佈)和評估模型(評估新數據在擬合分佈下的概率)的過程中,我們需要對分佈進行乘法運算。共軛關係意味著這些乘積都可以以封閉形式整潔地計算得出。
CH4 擬和機率模型
這章節的目標是將機率模型擬和到資料$${x_i}^I_{i=1}$$,這個過程稱為學習learning,目標是找到模型的參數組$$\theta$$。此外我們也學習如何用學習後的模型對新的數據$$x^*$$計算出他的機率,這過程evaluating the predictive distribution。
在這章我們探討三種方法
- maximum likelihood
- maximum a posteriori
- Bayesian approach
maximum likelihood
maximum likelihood目標是要找到一組參數$$\hat{\theta}$$使得資料$${x_i}^I_{i=1}$$出現的機率最大化。而計算likelihood function 在單一個資料點$$x_i$$,也就是$$Pr(x_i|\theta)$$,我們只需在$$x_i$$處評估概率密度函數。
假設每一個資料點都是從分布中獨立被取出的,那麼所有資料點的機率$$Pr(x_{i…I}|{\theta})$$就是所有單獨資料點代入likelihood function的乘積。因此要maximum likelihood可以寫成
$$\hat{\theta} = argmax_{\theta}[Pr(x_{i…I}|{\theta})] =argmax_{\theta} [\prod_{i=1}^I Pr(x_i|\theta)]$$
式子中的$$argmax_{\theta}f[\theta]$$是指找到一組參數組$${\theta}$$,讓$$argmax_{\theta}f[\theta]$$最大化。
要計算新資料$$x^*$$的predictive distribution,只需將新資料和我們找到的參數組帶入likelihood function,計算出機率即可。
Maximum Posteriori
在Maximum Posteriori(MAP)擬合中,我們引入有關參數$$\theta$$的先驗信息。由於我們可能對可能的參數值有所了解。例如,在時間序列中,時間 t 的參數值可以告訴我們在時間 t + 1 可能的值,於是將此信息將被編碼在先驗分佈中。
如同它的名稱,Maximum Posteriori方法將會找到一組參數組$$\hat{\theta}$$,使得Posteriori probability $$Pr(\theta|x_{i…I})$$最大化。
$$\hat{\theta} = argmax_{\theta}[Pr(\theta|x_{i…I})]$$
$$ =argmax_{\theta} [\frac{Pr(x_{i…I}|\theta)Pr(\theta)}{Pr(x_{i…I})}]$$
$$ =argmax_{\theta} [\frac{\prod_{i=1}^I Pr(x_i|\theta)Pr(\theta)}{Pr(x_{i…I})}]$$
在這裡第一行可以由貝葉斯定理推得第二行。另外由於我們找的是參數組$$\theta$$的最大值,所以分母的常數$$Pr(x_{i…I})$$是可以忽略的。因此我們可以將式子簡化成
$$\hat{\theta} = argmax_{\theta} [\prod_{i=1}^I Pr(x_i|\theta)Pr(\theta)]$$
我們可以發現他其實跟maximum likelihood只差了一項先驗分佈$$Pr(\theta)$$,所以maximum likelihood其實是maximum posteriori的一種特例,也就是maximum likelihood是$$Pr(\theta)$$是一個常數的情況。
Bayesian Approach
Bayesian Approach裡,我們不再把參數$$\theta$$當作一個常數,而是承認一件顯而易見的事實,參數組$$\theta$$可能不是唯一的。因此我們嘗試利用貝葉思定裡計算$$Pr(\theta|x_{i…I})$$,也就是在資料$$x_{i…I}$$出現的情況下,參數組$$\theta$$的機率分佈。
$$Pr(\theta|x_{i…I}) = \frac{\prod_{i=1}^I Pr(x_i|\theta)Pr(\theta)}{Pr(x_{i…I})}$$
而要驗證Bayesian Approach會比較複雜一點,因為跟前面不一樣我們沒有一個固定的參數組$$\theta$$可以帶入並且計算出機率,在這裡我們必須可能模型的機率分布。因此我們用以下方法計算。
$$Pr(x^*|x_{i…I}) = \int Pr(x^*|\theta)Pr(\theta|x_{i…I})d\theta$$
這條式子可以用以下方式解讀:
$Pr(x^*|\theta)$ 是對於給定的參數組 $$\theta$$,$$x^*$$出現的機率,因此這個積分可以視為使用不同的參數$$\theta$$所做出預測的加權總和,其中權重是由參數的posterior probability distribution $$Pr(\theta|x_{i…I})$$ 來決定的(代表我們對不同參數正確性的信心程度)。
統一三種方法的 predictive density calculations
如果我們將maximum likelihood, maximum posteriori 的參數的機率分布視為一種特例,也就是maximum likelihood, maximum posteriori參數分布全部集中在$$\hat{\theta}$$。正式的說法就是參數分布為一個以$$\hat{\theta}$$為中心的delta function。一個delta function $$\delta[z]$$是一個函式他的積分為1,而且在除了中心點z以外的任何地方都是0。我們將剛才predictive density帶入delta function,可以得到以下結果。
$$Pr(x^*|x_{i…I}) = \int Pr(x^*|\theta)\delta[\theta - \hat{\theta}]d\theta$$
$$= Pr(x^*|\hat{\theta})$$
ch4.4範例一
下面範例我們考慮擬和一個univariate normal model到一組數據$${x_i}^I_{i=1}$$。
首先univariate normal model的probability density function為
$$Pr(x|\mu,\sigma^2) = Norm_x[\mu,\sigma^2] = \frac{1}{\sqrt{2\pi\sigma^2}}exp[-\frac{(x-\mu)^2}{2\sigma^2}]$$
他有兩個參數平均$$\mu$$和變異數$$\sigma^2$$,首先我們從一個平均為1,變異數為1的normal distribution中取出$$I$$個數據$$x_{1…I}$$,我們的目標是利用前面的三種方法擬和抽取出來的數據集。
方法一Maximum likelihood estimation
對於觀測到的數據$Pr(x_{1…I}|\mu,\sigma^2)$$來說,參數 $${\mu,\sigma^2}$$ 的概率(likelihood) Pr(x_1…I |µ, σ^2) 是通過對每個數據點分別評估概率密度函數,然後取乘積得到的。
$$Pr(x_{1…I}|\mu,\sigma^2) = \prod_{i=1}^I Pr(x_i|\mu,\sigma^2)$$
$$= \prod_{i=1}^I Norm_{x_i}[\mu,\sigma^2]$$
$$= \frac{1}{\sqrt{2\pi\sigma^2}}exp[-\sum_{i=1}^I \frac{(x_i-\mu)^2}{2\sigma^2}]$$
很明顯的某些$${\mu,\sigma^2}$$參數組會使得likelihood比其他參數組還高。而且我們可以在二維平面視覺化各種參數組的likelihood,我們將以平均$$\mu$$和變異數$$\sigma^2$$為軸,而Maximum likelihood的解答就是在圖形的頂點(圖4.2)。也就是以下式子的解答。
$$\hat{\mu}, {\hat\sigma}^2 = argmax_{\mu,\sigma^2} [Pr(x_{1…I}|\mu,\sigma^2)]$$
理論上我們可以藉由微分$$Pr(x_{1…I}|\mu,\sigma^2)$$來求解,但是實際上$$Pr(x_{1…I}|\mu,\sigma^2)$$太複雜,因此我們可以將$$Pr(x_{1…I}|\mu,\sigma^2)$$取log,因為log是一個單調遞增函數,經過轉換後的$$Pr(x_{1…I}|\mu,\sigma^2)$$的最大值會在相同的地方。代數上,對數把各個數據點的可能性的乘積轉化為它們的總和,因此可以將每個數據點的貢獻分離出來。於是Maximum likelihood可以用以下方式計算。
$$\hat{\mu}, {\hat\sigma}^2 = argmax_{\mu,\sigma^2} [\sum_{i=1}^I log [Norm_{x_{i}}[\hat{\mu}, {\hat\sigma}^2]]]$$
$$= argmax_{\mu,\sigma^2} [-0.5Ilog[2\pi] - 0.5Ilog(\sigma^2) - 0.5\sum_{i=1}^I\frac{(x_i-\mu)^2}{\sigma^2}]$$
接著對對 log likelihood function L 進行$$\mu$$的偏微分。
$$\frac{\partial L}{\partial \mu} = \sum_{i=1}^I \frac{(x_i-\mu)}{\sigma^2}$$
$$= \frac{\sum_{i=1}^I x_i}{\sigma^2} - \frac{I\mu}{\sigma^2} = 0$$
整理後可以得到
$$\hat{\mu} = \frac{\sum_{i=1}^I x_i}{I}$$
利用類似的方利用類似的方法可以得到變異數$$\sigma^2$$的解答為
$$\hat{\sigma}^2 = \frac{\sum_{i=1}^I (x_i-\hat{\mu})^2}{I}$$
Least squares fitting
另外需要注意的是,很多文獻都是以最小二乘法來討論擬合的。我們使用maximum
likelihood來擬和正態分佈的平均參數$$\mu$$。將前面式子將$$\sigma^2$$視為常數可以得到
$$\hat{\mu} = argmax_{\mu,\sigma^2} [-0.5Ilog[2\pi] - 0.5Ilog(\sigma^2) - 0.5\sum_{i=1}^I\frac{(x_i-\mu)^2}{\sigma^2}]$$
$$= argmax_{\mu,\sigma^2} [-\sum_{i=1}^I(x_i-\mu)^2]$$
$$= argmax_{\mu,\sigma^2} [\sum_{i=1}^I(x_i-\mu)^2]$$
也就是說least squares fitting和使用maximum likelihood 估計常態分布的均值參數是等價的。
log likehood好處
likelihood function可以看到是許多乘法的結果,因此微分很不好算。
由於log函數是monotonic的關係,所以likelihood function經過log轉換後的最大值會在相同的地方,而且經過log轉換後乘法變成加法,因此微分變得容易許多。
https://bookdown.org/dereksonderegger/571/13-maximum-likelihood-estimation.html#likelihood-function
https://math.stackexchange.com/questions/3053131/why-are-the-local-extrema-of-a-log-transformed-function-equal-to-local-extrema-o
https://towardsdatascience.com/log-loss-function-math-explained-5b83cd8d9c83
方法二Maximum posteriori estimation
根據前面的定義,Maximum posteriori estimation的cost function為
$$\hat{\mu}, {\hat\sigma}^2 = argmax_{\mu,\sigma^2} [\prod_{i=1}^I Pr(x_i|\mu,\sigma^2)Pr(\mu,\sigma^2)]$$
$$= argmax_{\mu,\sigma^2} [\prod_{i=1}^I Norm_{x_i}[\mu,\sigma^2]NormInvGam_{\mu,\sigma^2}[\alpha,\beta,\gamma,\delta]]$$
在這裡我們選擇我們選擇了normal inverse gamma prior,其參數為α,β,γ,δ(圖4.4),因為它與normal distribution共軛。
在式子中的prior如下
$$Pr(\mu,\sigma^2) = \frac{\sqrt{\gamma}}{\sigma\sqrt{2\pi}}\frac{\beta^{\alpha}}{\Gamma(\alpha)}(\frac{1}{\sigma^2})^{\alpha + 1}exp[-\frac{2\beta + \gamma(\delta-\mu)^2}{2\sigma^2}]$$
而posterior distribution 與likelihood和prior的乘積成正比(見圖4.5),在與數據一致且先驗可信的區域具有最高的機率密度。
而跟maximum likelihood一樣我們利用把式子取log來計算最大值。式子如下
$$\hat{\mu}, {\hat\sigma}^2 = argmax_{\mu,\sigma^2} [\sum_{i=1}^I log [Norm_{x_{i}}[\mu, {\sigma}^2]] + log [NormInvGam_{\mu,\sigma^2}[\alpha,\beta,\gamma,\delta]]]$$
要找到MAP(maximum a posteriori)我們將式子拆成兩段並且分別對$$\mu$$和$$\sigma^2$$做偏微分。式子如下
$$\hat{\mu} = \frac{\sum_{i=1}^I x_i + \gamma\delta}{I + \gamma}$$
$$\hat{\sigma}^2 = \frac{\sum_{i=1}^I (x_i-\hat{\mu})^2 + 2\beta + \gamma(\delta-\hat{\mu})^2}{I + 3 + 2\alpha}$$
而平均數$\hat{\mu}$的解答可以進一步簡化
$$\hat{\mu} = \frac{I\bar{x} + \gamma\delta}{I + \gamma}$$
這式子是兩項的加權平均值,第一項是資料的平均$\bar{x}$並且以訓練樣本的數量$I$為權重,第二項是先驗分佈的參數$\delta$並且以先驗分佈的參數$\gamma$為權重
這裡給我們一些MAP(maximum a posteriori)的洞察。
- 當資料數量越多時,MAP的解會越接近資料平均(也就是ML(Maximum likelihood)的解)
- 當資料數量少一些的時候,MAP的解會在ML和prior的中間
- 當完全沒有資料的時候,MAP的解就是proir
方法三Bayesian estimation
在Bayesian estimation我們利用Bayesian定理計算參數的posterior distribution。
$$Pr(\mu, \sigma^2 | x_{1…I}) = \frac{\prod_{i=1}^I Pr(x_i|\mu,\sigma^2)Pr(\mu,\sigma^2)}{Pr(x_{1…I})}$$
$$= \frac{\prod_{i=1}^I Norm_{x_i}[\mu,\sigma^2]NormInvGam_{\mu,\sigma^2}[\alpha,\beta,\gamma,\delta]}{Pr(x_{1…I})}$$
$$= \frac{\kappa NormInvGam_{\mu,\sigma^2}[~\alpha,~\beta,~\gamma,~\delta]}{Pr(x_{1…I})}$$
在這裡likelihood和prior有共軛關係,而$\kappa$是 associated constant。Normal likelihood和normal inverse gamma prior的乘機產生出一個關於$\mu$$\sigma^2$的posterior distribution。其參數如下
$$~\alpha = \alpha + \frac{I}{2}$$
$$~\gamma = \gamma + I$$
$$~\delta = \frac{\gamma\delta + \sum_{i=1} x_i}{\gamma + I}$$
$$~\beta = \frac{\sum_{i=1} x_i^2}{2} + \beta + \frac{\gamma\delta^2}{2} - \frac{(\gamma\delta + \sum_{i=1} x_i)^2}{2(\gamma + I)}$$
需要注意的是,後驗分布(式4.20左側)必須是一個有效的概率分布,總和為一,因此共軛乘積中的常數 κ 和右側的分母必須完全抵消,才能得到:
$$Pr(\mu, \sigma^2 | x_{1…I}) = NormInvGam_{\mu,\sigma^2}[~\alpha,~\beta,~\gamma,~\delta]$$
現在我們可以看到conjugate prior的好處,我們保證可以得到關於參數的後驗分布的封閉形式表達式。
- Predictive density
跟maximum likelihood和MAP(maximum a posteriori)不一樣是,Bayesian estimation計算Predictive density的方式是我們計算每個可能參數集的預測值的加權平均值,其中加權由參數的後驗分布給出。
$$Pr(x_*|x_{1…I}) = \int \int Pr(x^*|\mu,\sigma^2)Pr(\mu,\sigma^2|x_{1…I})d\mu d\sigma^2$$
$$= \int \int Norm_{x^*}[\mu,\sigma^2]NormInvGam_{\mu,\sigma^2}[~\alpha,~\beta,~\gamma,~\delta]d\mu d\sigma^2$$
$$= \int \int \kappa(x^*, ~\alpha, ~\beta, ~\gamma, ~\delta)NormInvGam_{\mu,\sigma^2}[~\alpha,~\beta,~\gamma,~\delta]d\mu d\sigma^2$$
這裡我們又再次用到conjugate relation。積分包含一個與$\mu$和$\sigma^2$無關的常數乘以一個概率分布。將常數移到積分號外,可以得到:
$$Pr(x^*|x_{1…I}) = \kappa(x^*, ~\alpha, ~\beta, ~\gamma, ~\delta)\int \int NormInvGam_{\mu,\sigma^2}[~\alpha,~\beta,~\gamma,~\delta]d\mu d\sigma$$
因為pdf的積分為1,所以
$$= \kappa(x^*, ~\alpha, ~\beta, ~\gamma, ~\delta)$$
常數可以表示為:
$$\kappa(x^*, ~\alpha, ~\beta, ~\gamma, ~\delta) = \frac{1}{\sqrt{2\pi}}\frac{\sqrt{~\gamma}~\beta^{~\alpha}}{\sqrt{\v\gamma}\v\beta^{\v\alpha}}\frac{\Gamma(\v\alpha)}{\Gamma(~\alpha)}$$
其中
$$\v\alpha = ~\alpha + \frac{I}{2}$$
$$\v\gamma = ~\gamma + I$$
$$\v\beta = \frac{\sum_{i=1} x_i^2}{2} + ~\beta + \frac{~\gamma~\delta^2}{2} - \frac{(~\gamma~\delta + \sum_{i=1} x_i)^2}{2(~\gamma + I)}$$
在這裡我可以看到第二個使用conjugate prior的好處:可以計算積分,所以我們得到一個很好的封閉形式表達式來預測密度。
在有大量訓練數據的情況下,貝葉斯預測分布和最大事後概率(MAP)預測分布非常相似,但當數據量減少時,貝葉斯預測分布的尾部明顯更長。這是貝葉斯解決方案的典型特徵:它們在預測時更加中庸(不那麼確定)。在 MAP 的情況下,錯誤地承諾一個 µ 和 σ^2 的估計值導致我們對未來的預測過於自信。
ch4.5範例一
第二個範例我們考慮離散的資料${x_i}^I_{i=1}$其中$x_i \in {1, 2, …, 6}$。這種表達方式可以用來表達一個不均勻的骰子所出現的點數資料。我們將使用 categorical distribution來描述這些資料。
$$ Pr(x=k|\lambda_{1…K}) = \lambda_k $$
利用Maximum posteriori estimation和maximum a posteriori來推測六個參數${\lambda_k}^6_{k=1}$。而Bayesian方法則計算參數的probability distribution
4.5.1 Maximum Likelihood
為了找到Maximum Likelihood,我們要最大化每一個資料點的likelihood相乘的乘積
$$ \hat \lambda_{1…6} = argmax_{\lambda_{1…6}}[\prod^I_{i=1}Pr(x_i|\lambda_{1…6})] \qquad s.t. \sum_k \lambda_k = 1$$
$$ = argmax_{\lambda_{1…6}}[\prod^I_{i=1} Cat_{x_i}[\lambda_{1…6}]] \qquad s.t. \sum_k \lambda_k = 1$$
$$ = argmax_{\lambda_{1…6}}[\prod^6_{k=1}\lambda^{N_k}_k] \qquad s.t. \sum_k \lambda_k = 1$$
其中$N_k$代表在訓練資料中觀察到k的總次數。跟前一個例子一樣,利用log probability來協助尋找最大值。
$$ L = \sum^6_{k=1}N_klog[\lambda_k] + \nu(\sum^6_{k=1}\lambda_k - 1) $$
在這個式子中利用了 Lagrange multiplier $\nu$ 來達成$\sum^6_{k=1} \lambda_k = 1$的限制。接著我們對L對於$\lambda_k$和$\nu$微分並且將導數設為0,可以得到下式。
$$ \hat \lambda_k = \frac{N_k}{\sum^6_{m=1}N_m} $$
換句話說$\lambda_k$和觀察到k的次數成正比。
4.5.2 Maximum a posteriori
要找到 maximum a posteriori 首先要定義一個prior。我們選擇和categorical likelihood共軛的 Dirichlet distribution。式子如下。
$$ \hat \lambda_{1…6} = \underset{\lambda_{1…6}}{\mathrm{argmax}}[\prod^I_{i=1}Pr(x_i|\lambda_{1…6})Pr(\lambda_{1…6})]$$
$$ = \underset{\lambda_{1…6}}{\mathrm{argmax}}[\prod^I_{i=1}Cat_{xi}[\lambda_{1…6}]Dir_{\lambda_{1…6}}[\alpha_{1…6}]]$$
$$ = \underset{\lambda_{1…6}}{\mathrm{argmax}}[\prod^6_{k=1}\lambda_k^{N_k}\prod^6_{k=1}\lambda_k^{\alpha_k-1}]$$
$$ = \underset{\lambda_{1…6}}{\mathrm{argmax}}[\prod^6_{k=1}\lambda^{N_k + \alpha_k -1}_k] $$
接著和 maximum likelihood一樣利用 Lagrange multiplier來達成$\sum^6_{k=1} \lambda_k = 1$的限制。Maximum a posteriori推估參數的式子如下。
$$ \hat \lambda_k = \frac{N_k + \alpha_k -1}{\sum^6_{m=1}(N_m + \alpha_m - 1)}$$
其中$N_k$代表訓練資料中k出現的次數,這裡注意到如果$\alpha_k$全部設為1的時候,式子就變成跟 maximum likelihood的解一樣。
4.5.3 Bayesian Approach
在Bayesian approach中我們計算對於參數的posterior。
$$Pr(\lambda_1 … \lambda_6|x_{1…I}) = \frac{\prod^I_{i=1}Pr(x_i|\lambda_{1…6})Pr(\lambda_{1…6})}{Pr(x_{1…I})}$$
$$=\frac{\prod^I_{i=1}Cat_{x_i}[\lambda_{1…6}]Dir_{\lambda_{1…6}}[\alpha_{1…6}]}{Pr(x_{1…I})}$$
$$=\frac{\kappa(\alpha_{1…6}, x_{1…I})Dir_{\lambda_{1…6}}[~\alpha_{1…6}]}{Pr(x_{1…I})}$$
$$=Dir_{\lambda_{1…6}}[~\alpha_{1…6}]$$
其中$~\alpha_k=N_k+\alpha_k$。我們再次利用共軛關係,以產生具有與先驗分布相同形式的後驗分布。為了確保左邊的概率分布有效,常數κ必須再次與分母相抵消。
Predictive Density
Maximum Likelihood和Maximum a posteriori計算Predictive Density的方式就是把新的資料點代入求出來的參數。注意到如果prior是uniform(也就是$\alpha_{1…6}=1$),則MAP和ML會完全一樣,而預測結果會和觀察資料的頻率一樣。
對於Bayesian Approach,我們計算每個可能的參數集的預測的加權平均值,其中加權由參數的後驗分布給出。
$$Pr(x^*|x_{1…I})=\int Pr(x^*|\lambda_{1…6})Pr(\lambda_{1…6}|x_{1…I})d\lambda_{1…6}$$
$$=\int Cat_{x^*}[\lambda_{1…6}]Dir_{\lambda_{1…6}}[~\alpha_{1…6}]d\lambda_{1…6}$$
$$=\int \kappa(x^*, ~\alpha_{1…6})Dir_{\lambda_{1…6}}[\breve\alpha_{1…6}]d\lambda_{1…6}$$
$$=\kappa(x^*, ~\alpha_{1…6})$$
在這裡,我們再次利用共軛關係,得到一個常數乘以一個概率分布,而積分則簡單地等於該常數,因為概率分布的積分為一。
$$Pr(x^*=k|x_{1…I})=\kappa(x^*, ~\alpha_{1…6})=\frac{N_k+\alpha_k}{\sum^6_{j=1}(N_j+\alpha_j)}$$
再次強調貝葉斯預測密度比 ML/MAP解更不自信。特別是,儘管在訓練數據中從未觀察到$x^*=4$這個值,但它並未將觀察到該值的概率分配為零。這是合理的;僅僅因為在15次觀察中我們並未抽到4這個數字,並不意味著我們將永遠不會看到它。我們可能只是運氣不好。貝葉斯方法將這一點納入考慮,並給予這個類別一個小的概率。
CH5 The normal distribution
回顧第三章 multivariate normal distribution有兩個參數:平均$\mu$和變異數$\Sigma$。Proability density function為:
$$Pr(x) = \frac{1}{(2\pi)^{D/2}|\Sigma|^{1/2}}exp[-0.5(x - \mu)^T\Sigma^{-1}(x-\mu)]$$
或是簡短的
$$Pr(x)=Norm_x[\mu, \Sigma]$$
5.1 covariance矩陣的種類
covariance矩陣有三種類型
- spherical:對角元素全部都是同樣的正數,而且除了對角元素以外都是0
- diagonal:對角元素數字不一樣且均為正數,而且除了對角元素以外都是0
- full covariances:所有元素都不為0的正數,此外矩陣式對稱的也就是$\sigma_{12}^2=\sigma_{21}^2$
對於bivariate的情況spherical covariances產生出圓的圖形,Diagonal covariances產生出橢圓的圖形,而且橢圓的主軸和座標軸重疊,Full covariances產生出橢圓但是他的主軸方向可以是任意方向。
如果為 covariance 為 spherical 或 diagonal,則個別的變數均為獨立的,也就是
$$Pr(x_1, x_2) = Pr(x_1)Pr(x_2)$$
5.2 Decomposition of covariance
利用幾何的觀點可以Decomposition full covariances matric。想像一下有一個新的座標軸對齊full covariances所產生的橢圓圖形的兩個主軸,在這個新的座標軸上觀察這這個圖形,他的covariance matric就變成diagonal covariance matric。所以用座標轉換的觀點,我們可以得到新坐標軸上的diagonal covariance matric和原作標軸上full covariances matric的關係。其中R為座標旋轉矩陣。
$$\Sigma_{full}=R^T\Sigma’{diag}R$$
拆解過後,$\Sigma’{diag}$裡面隱含了varience,也就是在新座標軸上圖形的寬度資訊,因此可以再利用eigen-decomposition得在空間中哪一個方向對圖形比較重要。
multivariate normal pdf 經過線性轉換後,依然是一個multivariate normal,而轉換後的multivariate normal他的mean和covarience會和轉換前的multivariate normal有關,也和線性轉換方程式的$y=Ax+b$的係數和常數有關。
這個關係讓我麼可以簡化抽樣normal distribitaion的過程。假設想要從mean為$\mu$和covarianc為$\Sigma$的normal distribitaion抽樣,首先我們可以先從一個standart normal distribution抽樣一個點(mean $\mu=0$, covariance $\Sigma=I$),接著套用Linear transformations $y=\Sigma^{1/2}x+\mu$